The Box Model is a recurring concept in Web development. In HTML you can think of elements as boxes that may contain other boxes. This view of elements allows us to realize why proper nesting is so important. Generally, the browsers expect the elements to conform to this structure. When the nesting is not proper, then the imaginary boxes are intersecting with each other. If you can imagine yourself as a browser, then you would know how this is going to be difficult to interpret for you. In the same way, browsers try to interpret improper nesting as best as they can. Sometimes they succeed and other times they don’t. As as developer, it is your duty to ensure that you are providing as much correct information to the browser as possible. Doing this will ensure that most of your website’s users are getting the best experience they possibly can.

Every web page must have a root element called the HTML element. All the other HTML elements must be nested within that root element. Usually, it can have a lang attribute which indicates the language of the HTML document.
<html lang="en-US"> </html>
The head element contains all the elements which do not contribute to the display area of the web page. Some of the common elements found in this section are title, meta, link and script elements. Each of these elements provides additional info on the web page. Some websites like search engines use the information inside the head element to understand the web page better.
<!DOCTYPE html> <html lang="en-US"> <head> <meta charset="utf-8"> <title>This is the head section.</title> </head> <body> <p>This is the body section.</p> </body> </html>
The body element contains all of the remaining elements of the web page that contribute to the display area. When a change is applied to this element through means of CSS or JavaScript, it is applied to all of the elements within it. Thus the most common way to apply rules for the entire display portion of the web page is to apply them to the body element.
Since the HTML5 standard designated the body and head element as optional, it is not required to have them in a web page. But since they have been in use for so long and the way in which they separate meta information from display information in web pages is still useful for many. So, many developers will still use these elements for the near future.Here is a perfectly valid example without head and body elements.
<!DOCTYPE html> <html lang="en-US"> <meta charset="utf-8"> <title>This is the head section.</title> <p>This is the body section.</p> </html>
The hello world web page is the most basic working example of an HTML document. It has all the elements that would be present in every web page on the web. Here is the program if you missed it in the last lesson:
<!DOCTYPE html> <html lang="en-US"> <head> <meta charset="utf-8"> <title>My first web page</title> </head> <body> <p>Hello World!</p> </body> </html>
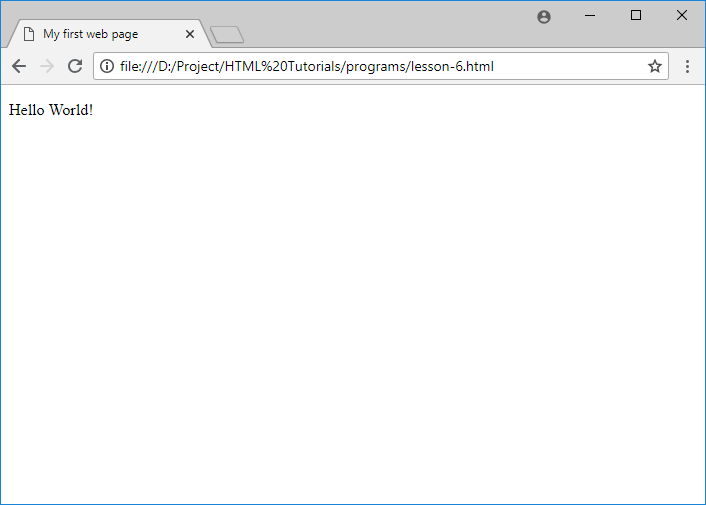
The output will be the following line when opened in a browser.
Hello World!
Here is an image of the web page in a browser:
Now it is time to type and run your first web page. Follow the steps below:
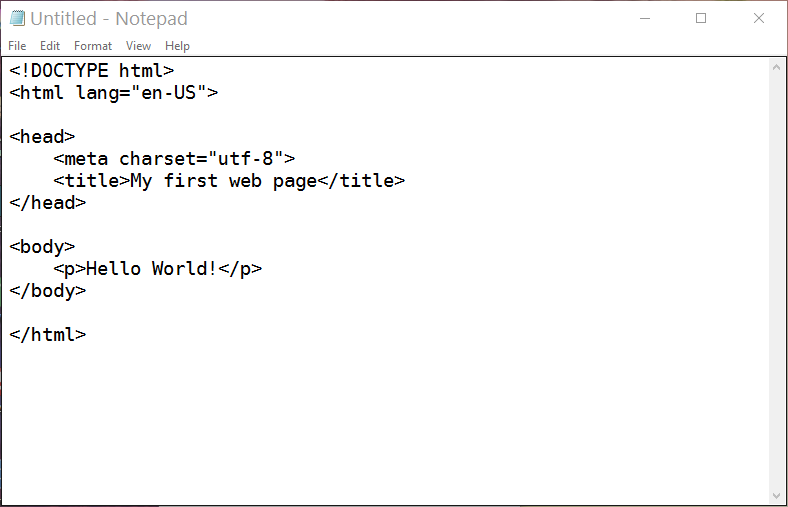
If you have chosen a text editor to enter the following code as it is.
<!DOCTYPE html> <html lang="en-US"> <head> <meta charset="utf-8"> <title>My first web page</title> </head> <body> Hello World! </body> </html>
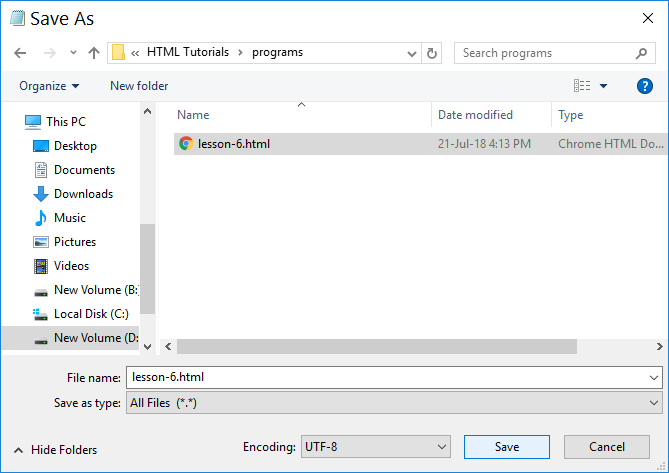
Save as an .html or .htm file.
If you are using notepad change Encoding to UTF-8 and Save as type as All Files. This makes sure that the file is saved as example.html, not example.html.txt.
Open the HTML file in your browser by dragging the file in the file explorer and dropping it in the browser window.

There are three classes of editors that help in the creation of web pages written in HTML. They have varying degrees of usability and can speed up development. The only catch is that they have increasing learning curves to use them more effectively. The classifications are:
Each of these options has their own pros and cons. The end product will be the same but the duration needed for achieving that product will be different for different options.
The advantage of using plain text editors is that they already come preinstalled with every system. Since they are good to go out of the box they are useful for beginners to get started as soon as possible.
Notepad
Notepad is the default editor for Windows. Do any one of the following:
Notepad for Windows
TextEdit
TextEdit is the default editor for Mac.
The obvious disadvantage of using such barebones editors is that they don’t have features that could speed up the making of web pages in HTML. Even switching to the next in class code editors could provide more useful features than sticking with plain editors.
There are hundreds of code editors that provide tons of features that can help the process of creating web pages in HTML. Essential features like Syntax highlighting and Autocompletion make finding errors and churning out web pages easy. The time required for marking up of content is significantly reduced compared to plain text editors.
Some of the popular code editors with a focus on HTML are:
Atom
Atom is a free and open source text editor from Github. It supports multiple programming languages, markup languages, and stylesheet languages. This includes HTML, CSS, and JavaScript. It has features like syntax highlighting, auto code completion and plugin support.
Brackets
Brackets is a free and open source text editor from Adobe. It supports multiple programming languages, markup languages, and stylesheet languages. This includes HTML, CSS, and JavaScript. It has features like syntax highlighting, auto code completion, live preview and plugin support. It is entirely written in HTML, CSS, and JavaScript.
Sublime Text Editor
Sublime is a commercial text editor with a free version with no expiry date. It supports multiple programming languages, markup languages, and stylesheet languages. This includes HTML, CSS, and JavaScript. It has features like syntax highlighting, auto code completion, split windows for editing multiple files.
Notepad++
Notepad++ is a free and open source text editor. It supports multiple programming languages, markup languages, and stylesheet languages. This includes HTML, CSS, and JavaScript. It has features like syntax highlighting.
Visual Studio Code
Visual Studio Code is a good open source editor from Microsoft. It is a feature packed editor that can be expanded using extensions.
The only obvious disadvantage to these editors is that since they have to be downloaded separately and set up to be used.
IDEs are most commonly used in software development because they have all of the tools in a single place. This makes workflows more streamlined for development. They have builtin features for debugging, which means that they are able to be used for finding and fixing errors and bugs easily. Most of the tools for deploying to the web comes along with these packages. The most commonly used IDEs for web development are:
The disadvantage of IDEs is that they have a steep learning curve in order to utilize all of their features which can be scary for beginners. They are more suitable for complex projects involving lots of languages.
Using plain text editors while learning HTML can help in understanding concepts. After a while switching to one of the advanced editors like brackets can help in understanding the benefits of code editors. Since there is no rule that only one editor should be used, we can also install multiple editors and experiment with them.
Attributes in HTML are helpful for providing additional information about an HTML element that is not part of the content. Each HTML element can have its own set of attributes. An attribute can have a single value for a particular HTML element. An element cannot have two attributes with the same name.

The general format for specifying HTML attributes is
<tagname attribute="value">Content </tagname>
for empty elements:
<tagname attribute="value" />
Here tagname is supposed to be one of the actual tags, attribute is a placeholder for an actual attribute in HTML and value is supposed to be an acceptable value for that particular attribute.
Similiar to how elements can be empty and don’t have content, attributes can also be empty. In this case, the value of the attribute is considered to be the same as the name of the attribute.
The below is usual format
<tagname attribute="attribute">Content </tagname>
The above can be written as
<tagname attribute >Content </tagname>
Both of the above representations are correct and are valid for composing web pages.
Since HTML is a fairly lenient markup language, the quotes around the value of an attribute could be omitted entirely. But in certain situations, it will cause a problem. When an attribute’s value is supposed to be multiple words instead of one, the browser cannot correctly determine the attribute’s value. Instead, it only recognizes the first word and the rest of the words become empty attributes. This is not what we would need.
<tagname attribute=Many Words>Content goes here.</tagname>
The solution is to put quotes around multiple words:
<tagname attribute="Many Words">Content goes here.</tagname>
Another possible problem is that the value itself may contain quotes. In this case, if the quotes inside of the value are of the same type, then we can use the other type for wrapping around values. For example, if single quotes are needed then we can wrap the value with double quotes and vice versa. But if need multiple types of quotes then one of the quotes have to be escaped using the HTML entities like ' and " for single and double quotes respectively.
<tagname attribute="Dwayne 'The Rock' Johnson"></tagname> <tagname attribute='Dwayne "The Rock" Johnson'></tagname> <tagname attribute="Dwayne 'The Rock' Johnson"></tagname> <tagname attribute='Dwayne "The Rock" Johnson'></tagname>
All of the above methods are valid and correct ways of quoting values in HTML.
The final problem regarding quotes occurs if they are mismatched. In this case, the browser interprets all the portion after the mismatched quotes as still part of the attribute’s value until another matching quote is found. This could lead to entire sections of pages being rendered invisible. This problem can potentially be avoided when using editors with syntax highlighting. Since attribute values are colored differently in such editors we are able to quickly identify this particular problem when this occurs. An example of mismatched attributes:
<tagname attribute="value'></tagname>
A web page consists of several elements in various combinations and order. Elements are the fundamental building blocks of the web pages. Usually, an element consists of three parts:

The format for a typical HTML element is
<tagname>Content goes here...</tagname>
Here tagname is a placeholder for one of the actual HTML tags.
In HTML tags are the basic concepts used for marking up the web pages. The purpose of HTML tags is to literally markup or enclose sections of web pages to describe the type of content the sections represent. A web page can be imagined as a simple text file marked up using tags.
The format for representing an opening tag in HTML is
<tagname>
The format for representing a closing tag in HTML is
</tagname>
Here tagname represents the type of content like para, image, video, audio, etc…
The combination of the opening tag and closing tag with the content makes up an element.
Some elements in HTML have no content. Such HTML elements are called Empty elements. There are two ways of representing empty HTML elements:
<tagname>
<tagname />
The second type visually implies that the tag is an empty element. But since both formats of representation are accepted in latest HTML5 standards, choosing any one method and sticking with it throughout the web page will make your style consistent.
For this tutorial, we will be following the much simpler first approach.
HTML elements can be nested, i.e. elements can contain other elements as content. Nesting of HTML is a common practice in HTML to the extent that it is nearly impossible to find an HTML document without nested elements. In fact, all HTML elements must be nested inside the root element <html>.
An example of properly nested elements:
<p>May the <em>force</em> be with you.</p>
We can say that the elements are properly nested if they are closed in the reverse order of opening. This is to ensure that the inner elements are completely wrapped around by their parent elements. This ensures that the browser knows exactly how to display the nested elements. When the elements are not properly nested, the browser tries to guess what the correct order would be. In some simple cases, it may even correctly guess the order and render the web page correctly. In other situations, it may fail to do so and some sections may be missing entirely. So it would be wise to properly nest the elements the first time around to avoid headaches in the future. Most of the modern code editors make this easy since they create the ending tags almost immediately in the correct order.
An example of an improperly nested code:
<p>This is supposed to be <b>bold.</p></b>
A web browser is a software which gets web pages made up of HTML from a server on the internet or on the computer, processes those web pages and displays the content as described by the HTML document. A browser can display text, images, videos and play audio. Chances are that you are reading this tutorial in your favorite browser right now.
Yes, every computer comes with a browser preinstalled. Many people tend to install another browser once they open a new device. While for purpose of browsing on the internet your current browser may be sufficient. But for the purpose of learning Web Design, we recommend you to get hold of multiple popular browsers. This makes it possible to ensure that the web pages you create, work correctly for the majority of your audience.
There are tons of browsers available to download over the internet. Most of them can be downloaded for free. Some of the browsers are more popular than others. This can be due to a variety of reasons like availability, ease of use, integration across multiple devices and so on.
The most popular modern browsers for the Desktop platforms that can be downloaded from the internet for free are:
The above is not an exhaustive list. There may be other browsers used by your audience. New browsers can rise to prominence in no time and popular browsers can go out of the mainstream after a while. Only Time can tell.
Mobile phones have been on the rise and are increasingly replacing Desktops and Laptops for connecting to the internet for purposes like email, social networking, and browsing. This means that there have been the development of hundreds if not thousands of browsers for mobile platforms like Android, iOS, and Windows. As you can see the mobile browser market is diverse and there can be no subset of browsers that can be considered to ensure that our web pages will display flawlessly. In this case, the responsibility falls on the shoulders of developers to ensure that web pages are responsive i.e the pages can adapt to the various screens like desktops, tablets, and phones. Some of the techniques for responsive development will also be taught in this tutorial.
Special mentions of some Mobile Browsers
HTML stands for HyperText Markup Language. It is the primary language used for the development of web pages and web apps on the internet. It uses concepts like tags and attributes for describing various content types in a webpage like paragraphs, titles, headings, images, video, audio, etc,…
HTML is part of the triad of languages used for developing modern websites and web pages. The three languages are:
In short, we can say that web pages are made using HTML, styled using CSS and given interactivity using JavaScript. Learning one or all of these languages will help in understanding how the Web works.